How to open CSV files in QGIS
30.05.2012 18:51 · GIS · qgis, howto
Recently, there have been a lot of questions about working with CSV files in QGIS. So here is my attempt to shed some light on this complex and confusing topic. Be prepared for a longread.
So what is CSV? CSV (comma-separated values) is a text format for storing tabular data. A CSV file contains records, each of which is made up of fields separated by a specific delimiter. Despite its simplicity and the existence of RFC 4180, CSV is not a single, well-defined format. In practice, the word CSV refers to any file containing values separated by any separator.
RFC 4180 compliant file:
XCOORD,YCOORD,CATEGORY,NAME,TYPE
-9.2057202,38.6935901,attraction,Padrão dos Descobrimentos,monument
-9.2179075,38.692625,museum,Forte do Bom Sucesso,castle
-9.1983022,38.70763,museum,Palácio Nacional da Ajuda,castle
-9.2156419,38.6947058,fountain,Chafariz da Praia de Belém,attraction
The same data, but with a different delimiter (not RFC 4180 compliant, but still a CSV file).
XCOORD;YCOORD;CATEGORY;NAME;TYPE
-9.2057202;38.6935901;attraction;Padrão dos Descobrimentos;monument
-9.2179075;38.692625;museum;Forte do Bom Sucesso;castle
-9.1983022;38.70763;museum;Palácio Nacional da Ajuda;castle
-9.2156419;38.6947058;attraction;Chafariz da Praia de Belém;fountain
Now it should be more or less clear what the format is. Let’s see how these files can be used in QGIS.
Technical note
Support for different data sources in QGIS is implemented using so-called “data providers”. These are regular shared libraries that implement a specific interface (set of functions). Some data providers can only work with one specific data source, such as the PostgreSQL provider, while others support multiple data sources, such as the GDAL data provider. So very often the same file or data source can be opened with two or more providers. And due to the fact that different providers have different capabilities, opening a file with the wrong provider can make you, um… frustrated and urge you to post angry feedback on forums or mailing lists.There are two data providers in QGIS that “understand” the CSV format:
delimitedtext(specialised)ogr(universal)
To use the delimitedtext provider, the “Add Delimited Text Layer” plugin must be enabled. On the other hand, the ogr provider works out of the box and does not require any plugins to be enabled.
Using delimitedtext provider
This provider only supports CSV files with a spatial component. Spatial information can be defined either as columns with X and Y coordinates, or as a column with geometry definition in WKT (Well-Known Text) format. It is not possible to open non-spatial tabular data with this provider, for example, to join it to an attribute table of another layer. Another limitation is that layers created by the provider cannot be edited in QGIS. Of course, you can export the created layer to another format, such as a shapefile, but there are some other issues to be aware of, which are described below.
As mentioned above, to use this provider, you need to activate the “Add Delimited Text Layer” plugin. To do this, first go to “Plugins → Manage plugins”, find the required plugin in the Plugin Manager dialogue and enable it if it is not already enabled. The plugin adds its button to the “Layers” panel and to the “Layer” menu.

The QGIS manual provides detailed instructions on how to use the plugin, so I won’t repeat them here. After clicking on the plugin button, the following window will appear.
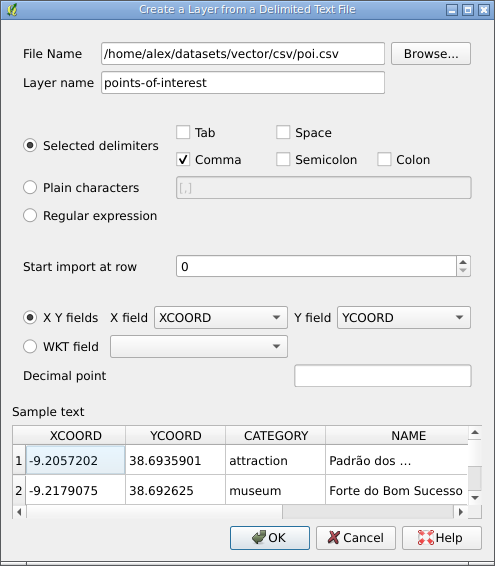
The “File Name” field specifies the imported CSV file; the “Layer Name” field is filled in automatically, the layer name will be the same as the file name without suffix, if desired/needed it can be changed. Immediately after selecting a file, the module will analyze it using the specified delimiters and display the result in the preview area at the bottom of the window. Two situations are possible at this stage:
- an appropriate delimiter is selected, and the data is displayed correctly in the preview area
- the delimiter in the file and the one selected in the plugin do not match, and the data in the preview area is displayed incorrectly (columns are “glued” or extra columns appear)
In the latter case, you must set the correct delimiters using the preset values or by entering your own delimiter (as a plain text or a regular expression).
If you do not need all the data but only some of it, you can specify the row number from which you want to start the import. Note, however, that in this case you will have to say goodbye to the normal column headings: instead of them, you will have the contents of the previous row. If necessary, specify in the “Decimal point” field the separator to be used to separate the integer and fractional parts. Finally, depending on the format used for the spatial component, we should specify either fields with X and Y coordinates (if we have point data and the coordinates are specified in separate columns) or a field with a geometry description in WKT format (any geometry type supported by QGIS). In both cases, the coordinates can be in any CRS.
After pressing the “OK” button, the new layer is created and added to the map, and the user is asked to specify the coordinate system for the newly created layer. The data can then be used just like any other layer. It should also be noted that the plugin recognises fields with different data types and creates fields of the appropriate type (Integer, Real, String), but this process cannot be controlled and fine-tuned.
When exporting a layer created with the “Add Delimited Text Layer” plugin to another format, it is necessary to take into account the specifics of the corresponding OGR driver. For example, the shapefile driver creates text fields with a default length of 80 characters, which in some cases can lead to loss of information during export.
This provider is therefore best suited for the quick creation of spatial layers where the attribute component is not important or required.
Using ogr provider
This provider allows you to open any type of CSV files: with or without a spatial component. The data source can be either a single file or a directory of files. For a directory to be used as a data source, at least half of the files in it must be CSV files. In this case, each file will be opened as a separate layer/table.
GDAL requires the files to be in a certain format:
- a single line represents a single record
- there must be at least two fields in a line
- lines end with a DOS (CR/LF) or UNIX (LF) line feed
- all records must have the same number of fields
- fields must be separated by commas (
,). As of GDAL 1.7.0 it is possible to use semicolons (;) or tabs as delimiters. But there is a small nuance here: the automatic detection of the delimiter will only work if there are no other potential delimiters in the first line of the file - “complex” attribute values (i.e., containing commas, line breaks, quotation marks, etc.) must be enclosed in double quotation marks. If the attribute value contains double quotes, they must be escaped by adding another double quote to each double quote
When opening a file, GDAL tries to get the field names from the first line. However, if one or more fields are numeric, the first line is also treated as data and field names are generated using the pattern field_1…field_N. As of GDAL 1.9.0, numbers enclosed in double quotes are treated as field names.
If a file meets the above requirements, it can be opened in QGIS using the Add Vector Layer dialogue box. In this case, the file will open as a regular table, and all fields will be of the String data type. To get fields with the correct data type, a special file with information about the data type of each field must be created. This is a plain text file whose name must be the same as the CSV file name, but with a .csvt extension. It will contain only one line specifying the data type of each field, enclosed in double quotes and separated by commas. The supported data types are:
IntegerRealStringDate(inYYYY-MM-DDformat)Time(inHH:MM:SS+nnformat)DateTime(inYYYY-MM-DD HH:MM:SS+nnformat)
For the first three data types, you can specify the field length in brackets, and for real values, you can specify the number of decimal places. For example, for the CSV file above, the corresponding .csvt file will look like this:
"Real","Real","String","String","String"
or with defined field length and precision
"Real(10.6)","Real(10.6)","String(50)","String(255)","String(50)"
Note
You need to open a.csv file, not a .csvt file.A CSV file can contain spatial information: either two (three) columns with X, Y (Z) coordinates of points or a field with a geometry definition in WKT format. By default, such files are also opened as a geometryless tables. To open them as a vector layer, you need to create a special XML file, a so-called VRT file.
The root element of the VRT file is OGRVRTDataSource. A nested OGRVRTLayer element is created for each layer. The OGRVRTLayer element must have a name attribute with the name of the layer and can contain several nested elements. The full list of elements can be found on the page describing the VRT driver in GDAL. Here, we will only look at the elements needed to open CSV files as a vector layer. So:
SrcDataSource. The value of the element is the name of the dataset, in our case, the path to the CSV file. In general, any OGR-compatible source can be a dataset. The element may also have two optional attributes:relativeToVRT— default value0, if the value is1, the data source will be treated as defined by a relative pathshared— controls the opening mode. The default value forSrcLayerisOFF
SrcLayer. The name of the layer in the dataset from which the virtual layer is created. When used with a CSV file, the layer name must be the same as the file name without the suffix. For example, if the file name ismyfile.csvthen the layer name will bemyfileGeometryType. The geometry type of the layer. If not specified, the geometry type of the original layer is used. The following values are supported:wkbNone,wkbUnknown,wkbPoint,wkbLineString,wkbPolygon,wkbMultiPoint,wkbMultiLineString,wkbMultiPolygon, andwkbGeometryCollection. If necessary, the suffix25Dcan be added to the geometry types listed above when using the Z coordinate. The default value iswkbUnknown, i.e., any type of geometry is allowedLayerSRS(optional). The value of this element is a description of the layer coordinate system in WKT format or any other format supported by theOGRSpatialReference::SetUserInput()method. If not specified, the coordinate system of the source layer is used. IfNULLis specified, the output layer will have no coordinate systemGeometryField(optional). This element describes the geometry of the virtual layer. If the element is missing, the geometry of the source objects is copied. The way the geometry is defined is specified by theencodingattribute, which can take one of the valuesWKT,WKBorPointFromColumns. IfWKTorWKBis used, thefieldattribute must be present, and its value should be the name of the field with a geometry definition in WKT or WKB format. If theencodingattribute has the valuePointFromColumns, thex,yandzattributes must be present, and their values should be the names of fields with X, Y and Z coordinates, respectively. Thezattribute is optional. As of GDAL 1.7.0, you can also specify the optionalreportSrcColumnattribute to control whether the original geometry fields (i.e., the fields specified in thefield,x,y, andzattributes) of the original layer are present in the final layer. If this attribute is set toFALSE, the original geometry fields will only be used to create feature geometry and will not be displayed as table fieldsField(available as of GDAL 1.7.0). Used to describe the fields of a virtual layer. If these elements are missing, the virtual layer will have the same set of fields as the source file. EachFieldelement can have the following attributes:name(mandatory): field nametype: the data type of the field. Supported datatypes are:Integer,IntegerList,Real,RealList,String,StringList,Binary,Date,TimeandDateTime. Default isStringwidth: field size (length), defaults to unknownprecision: precision (number of decimal places) of the field, defaults to0src: the name of the source field whose values are to be used. By default, it is the same as the value of thenameattribute
Note
If you are using VRT files, you should open the VRT file and not the original CSV file.Let’s examine some examples. Suppose our CSV file looks like this:
XCOORD,YCOORD,CATEGORY,NAME,TYPE
38.6935901,-9.2057202,attraction,Padrão dos Descobrimentos,monument
38.692625,-9.2179075,museum,Forte do Bom Sucesso,castle
38.70763,-9.1983022,museum,Palácio Nacional da Ajuda,castle
38.6947058,-9.2156419,fountain,Chafariz da Praia de Belém,attraction
As you can see, the coordinates of the points are specified by the two fields XCOORD and YCOORD. In the simplest case, the VRT file will look like this:
<OGRVRTDataSource>
<OGRVRTLayer name="poi">
<SrcDataSource relativeToVRT="1">poi.csv</SrcDataSource>
<GeometryType>wkbPoint</GeometryType>
<LayerSRS>WGS84</LayerSRS>
<GeometryField encoding="PointFromColumns" x="XCOORD" y="YCOORD"/>
</OGRVRTLayer>
</OGRVRTDataSource>
In this case, all fields of the source file will be present in the virtual layer, and their data type will be String. Let’s add field definitions to have the correct data types:
<OGRVRTDataSource>
<OGRVRTLayer name="poi">
<SrcDataSource relativeToVRT="1">poi.csv</SrcDataSource>
<GeometryType>wkbPoint</GeometryType>
<LayerSRS>WGS84</LayerSRS>
<GeometryField encoding="PointFromColumns" x="XCOORD" y="YCOORD"/>
<Field name="XCOORD" type="Real" width="10" precision="6"/>
<Field name="YCOORD" type="Real" width="10" precision="6"/>
<Field name="CATEGORY" type="String" width="50"/>
<Field name="NAME" type="String" width="255"/>
<Field name="TYPE" type="String" width="50"/>
</OGRVRTLayer>
</OGRVRTDataSource>
Let’s give the fields readable names
<OGRVRTDataSource>
<OGRVRTLayer name="poi">
<SrcDataSource relativeToVRT="1">poi.csv</SrcDataSource>
<GeometryType>wkbPoint</GeometryType>
<LayerSRS>WGS84</LayerSRS>
<GeometryField encoding="PointFromColumns" x="XCOORD" y="YCOORD"/>
<Field name="Longitude" src="XCOORD" type="Real" width="10" precision="6"/>
<Field name="Latitude" src="YCOORD" type="Real" width="10" precision="6"/>
<Field name="Category" src="CATEGORY" type="String" width="50"/>
<Field name="Object name" src="NAME" type="String" width="255"/>
<Field name="Object type" src="TYPE" type="String" width="50"/>
</OGRVRTLayer>
</OGRVRTDataSource>
If the geometry in the source file is written in WKT format, as shown below
WKT_GEOM,CATEGORY,NAME,TYPE
POINT(-9.2057202 38.6935901),attraction,Padrão dos Descobrimentos,monument
POINT(-9.2179075 38.692625),museum,Forte do Bom Sucesso,castle
POINT(-9.1983022 38.70763),museum,Palácio Nacional da Ajuda,castle
POINT(-9.2156419 38.6947058),fountain,Chafariz da Praia de Belém,attraction
the VRT file will change slightly
<OGRVRTDataSource>
<OGRVRTLayer name="poi">
<SrcDataSource relativeToVRT="1">poi.csv</SrcDataSource>
<GeometryType>wkbPoint</GeometryType>
<LayerSRS>WGS84</LayerSRS>
<GeometryField encoding="WKT" field="WKT_GEOM"/>
<Field name="Category" src="CATEGORY" type="String" width="50"/>
<Field name="Object name" src="NAME" type="String" width="255"/>
<Field name="Object type" src="TYPE" type="String" width="50"/>
</OGRVRTLayer>
</OGRVRTDataSource>
One more thing: when using VRT and GDAL files >= 1.7.0, you don’t need to create a .csvt file because the data type can be defined directly in the .vrt file.